반응형

[데이터 중심 애플리케이션 설계] 11. 스트림 처리
1. 이벤트 스트림 전송
이벤트
- 특정 시점에 일어난 사건에 대한 세부 사항을 포함
- 일반적으로 일기준 시계를 따르는 타임스탬프 포함
이벤트의 부호화, 저장, 전송
- 텍스트 문자열이나 JSON 또는 이진 형태 등으로 부호화 가능
- 파일 및 관계형 테이블에 삽입 및 문서 데이터베이스로 기록하거나 저장 가능
- 다른 노드에서 처리하게끔 네트워트를 통해 전송 가능
생산자와 소비자
- 생산자(producer = publisher) : 이벤트를 만든다.
- 소비자(consumer = subscriber) : 이벤트를 처리한다.
- 스트림 시스템에서는 토픽(topic)이나 스트림으로 관련 이벤트를 묶는다.
1.1 메시징 시스템
- 메시징 시스템은 새로운 이벤트에 대해 소비자에게 알려준다.
- 생산자는 이벤트를 포함한 메시지 전송한다.
- 소비자는 그 메시지를 전달 받는다.
- 생산자와 소비자 연결
- 다수의 생산자 노드가 같은 토픽(topic)으로 메시지를 전송한다.
- 다수의 소비자 노드가 토픽(topic) 하나에서 메시지를 받아 간다.
1.1.1 생산자에서 소비자로 메시지를 직접 전달하기
- 많은 메시지 시스템은 중간 노드를 통하지 않고, 생산자와 소비자가 네트워크로 직접 통신한다.
직접 통신 예시
- UDP 멀티캐스트
- 낮은 지연이 필수인 주식 시장과 같은 금융 산업에서 널리 사용된다.
- UDP 자체는 신뢰성이 낮아도 애플리케이션 단의 프로토콜은 읽어버린 패킷을 복구 할 수 있다.
- 생성자는 필요할 때 패킷을 재전송할 수 있게 전송한 패킷을 기억해야 한다.
- 소비자가 네트워크 서비스를 노출하면 생산자는 직접 HTTP나 RPC 요청
직접 메시징 시스템의 한계
- 메시지가 유실 될 수 있는 가능성을 고려하여 애플리케이션 코드를 작성해야 한다.
- 소비자가 오프라인이라면 메시지를 전달하지 못하는 상태에서 있는 동안 전송된 메시지는 잃어 버릴 수 있다.
1.1.2 메시지 브로커
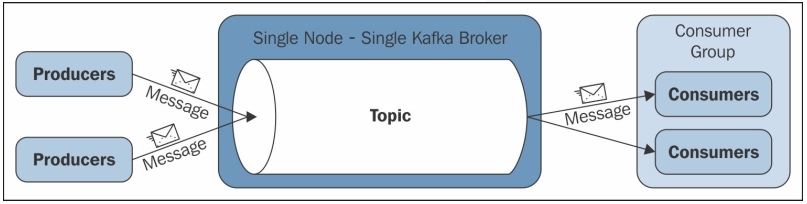
메시지 브로커란?
- 직접 메시징 시스템의 대안으로 메시지 브로커를 통해 메시지를 보내는 방법이 있다.
- 메시지 스트림을 처리하는데 최적화된 데이터베이스의 일종이다.
- 메시지 브로커는 서버로 구동되고, 생성자와 소비자는 서버의 클라이언트로 접속한다.
- 생성자는 브로커로 메세지 전송한다.
- 소비자는 브로커에서 메세지를 읽어 전송받는다.
메세지 브로커의 이점
- 클라이언트의 상태 변경(접속, 접속 해제, 장애)에 쉽게 대처할 수 있다.
- 브로커가 장애로 중단됐을 때도 메시지를 디스크에 기록하게 되면 유실되지 않는다.
- 메모리에만 메시지를 보관하는 브로커는 유실될 수 있다.
- 큐에 대기하게 되면 소비자는 비동기로 동작
- 생산자는 메시지를 브로커에 보내면 해당 메시지는 버퍼에 쌓이게 되고, 생산자는 메세지가 소비가 될 때까지 기다리지 않는다.
- 소비자는 메시지를 바로 소비할도 있지만, 늦게 소비할 수도 있게 된다.
1.1.3 메시지 브로커와 데이터베이스 비교
- 데이터 보관
- 데이터베이스 : 데이터가 삭제될 때까지 보관
- 메시지 브로커 : 소비자에게 데이터가 전달되면 자동으로 삭제
- 데이터 검색
- 데이터베이스 : 색인 등 다양한 검색 방법을 지원
- 메시지 브로커 : 특정 패턴과 부합하는 토픽의 부분 집합을 구독하는 방식 지원
- 메커니즘을 다르지만 둘 다 본질적으로 클라이언트가 데이터에서 필요한 부분만 선택하는 방법이다.
- 데이터 질의
- 데이터베이스 : 질의할 때 그 결과는 질의 시점의 데이터 스냅숏을 기준으로 한다.
- 데이터 변경되면 다시 질의하거나 풀링하지 않으면 변경되었다는 것을 알 수가 없다.
- 메시지 브로커 : 임의 질의를 지원하지 않지만, 데이터가 변경되면 클라이언트에게 알려 준다.
- 데이터베이스 : 질의할 때 그 결과는 질의 시점의 데이터 스냅숏을 기준으로 한다.
1.1.4 복수 소비자
여러 소비자가 같은 토픽에서 메시지를 읽을 때 사용하는 주요 패턴 2가지
- 로드 밸런싱
- 각 메시지는 소비자 중 하나로 전달된다.
- 브로커는 메시지를 전달할 소비자를 임의로 지정한다.
- 팬 아웃(fan-out)
- 각 메시지는 모든 소비자에게 전달된다.
- 여러 독립적인 소비자가 브로드캐스팅된 동일한 메시지를 서로 간섭 없이 전달 받을 수 있다.

- 이 두가지 패턴을 함께 사용 가능
- 두 개의 소비자 그룹에서 하나의 토픽을 구독한다.
- 각 그룹은 모든 메시지를 받지만, 그룹 내에서는 각 메시지를 하나의 노드만 받게 하는 식이다.
1.1.5 확인 응답과 재전송
- 소비자 장애
- 브로커가 메시지를 소비자에게 전달을 했지만, 처리하지 못하거나 부분적으로만 처리 후에 장애가 발생할 수 있다.
- 이럴 때는 메시지가 유실 될 수 있기 때문에 브로커는 확인 응답을 사용한다.
- 클라이언트는 메시지 처리가 끝났을 때, 브로커에게 명시적으로 알려주고 브로커는 해당 메시지를 제거한다.
- 확인 응답이 안되면?
- 확인 응답을 받지 전에 클라이언트가 연결이 되지 않거나, 타임아웃이 발생하면 브로커는 처리가 되지 않았다고 간주하고 다른 소비자에게 다시 전송한다.
- 메시지 처리가 되었는데도 불가하고 확인 응답 되지 않았다면, 원자적 커밋 프로세스가 필요하다.
1.2 파티션닝된 로그
- 패킷을 전송하거나 서비스에 요청하는 작업은 보통 영구적 추적을 남기지 않는 일시적 연산이다.
- 메시지 브로커는 소비자에게 전달된 후 즉시 삭제되는 일시적 보관 개념으로 만들어졌다.
- 메시지 브로커는 메시지를 전달 한 후 확인 응답을 받고 해당 메세지를 삭제하면 더이상 복구되지 않는다.
- 이후 소비자를 추가하면, 등록한 시점 이후의 메세지만 받을 수 있다.
1.2.1 로그를 사용한 메시지 저장소
- 로그 기반 메시지 브로커 : DB의 지속성 있는 저장과 메시징 시스템 지연 시간이 짧은 알림 기능의 조합
로그란?
- 단순히 디스크에 저장된 추가 전용 레코드의 연속이다.
- 로그 구조화 저장 엔진과 쓰기 전 로그, 복제본의 로그와 같은 맥락
브로커에서 로그는?
- 생산자가 보낸 메시지는 로그 끝에 추가한다.
- 소비자는 로그를 순차적으로 읽어 메시지를 받는다. 로그 끝에 도달하면 새 메시지가 추가됐다는 알림을 기다린다.
로그 파티셔닝
- 디스크 하나를 쓸 때보다 로그 처리량을 높이기 위해 파티셔닝을 하는 방법이다.
- 다른 파티션은 다른 장비에서 서비스할 수 있다.
- 각 파티션은 다른 파티션과 독립적으로 읽고 쓰기가 가능한 로그가 된다.
오프셋(offset)
- 각 파티션 내에서 브로커는 모든 메시지에 단순히 증가하는 순번인 오프셋을 부여한다.
- 다른 파티션 간 메시지의 순서는 보장하지 않는다.

로그 기반 메시지 브로커의 이점
- 초당 수백만 개의 메시지를 처리할 수 있다.
- 메시지를 복제함으로써 장애에 대비할 수 있다.
1.2.2 로그 방식과 전통적인 메시지 방식의 비교
로그 기반 접근법
- 팬 아웃 메시징 방식을 제공한다.
- 소비자가 서로 영향 없이 독립적으로 로그를 읽을 수 있고, 메시지를 읽어도 로그에서 삭제되지 않는다.
- 개별 메시지를 소비자 클라이언트에 할당하지 않고, 소비자 그룹 간 로드 밸런싱한다.
- 브로커는 소비자 그룹의 노드들에 전체 파티션을 할당할 수 있다.
1.2.3 소비자 오프셋
오프셋의 이점
- 파티션 하나를 순서대로 처리하면 메시지를 어디까지 처리했는지 알기 쉽다.
- 메시지마다 보내는 확인 응답을 추적할 필요가 없다.
- 추척 오버헤드가 감소하고 일괄 처리와 파이프라이닝을 수행 할 수 있는 기회를 제공하여 처리량을 늘리는데 도움을 준다.
소비자 노드 장애 발생시 문제점
- 소비자 노드가 장애가 발생하면 그룹내 다른 노드가 오프셋부터 메시지를 처리한다.
- 장애가 발생한 소비자가 처리하였지만, 오프셋이 기록되지 않았다면 두번 처리하게 된다.
1.2.4 소비자가 생성자를 따라갈 수 없을 때
- 소비자의 오프셋을 모니터링하면서 눈에 띄게 뒤쳐지는 경우에는 이를 경고를 한다.
- 운영자는 소비자 처리가 느린 문제를 고쳐 메시지를 잃기 전에 따라 잡을 시간을 충분히 벌 수 있다.
- 어떤 소비자가 너무 뒤쳐져서 메시지를 읽기 시작해도 해당 소비자만 영향을 받고 다른 소비자들의 서비스를 망치지는 않는다.
1.2.5 오래된 메시지 재생
메시지 브로커 비교
- AMQP, JMS 유형의 메시지 브로커
- 메시지를 처리하고 확인 응답하는 작업은 브로커에서 메시지를 제거하기 때문에 파괴 연산을 한다.
- 로그 기반 메시지 브로커
- 메시지를 소비하는게 오히려 파일을 읽는 작업과 더 유사한데 로그를 변화시키지 않는 읽기 전용 연산을 한다.
로그 기반의 이점
메시지 재처리는 몇번이든지 처리 코드를 변경해 재처리가 가능하다.
2. 데이터베이스와 스트림
2.1 시스템 동기화 유지하기
2.1.1 이중 기록(dual write)
- 주기적으로 데이터베이스 전체를 덤프하는 작업이 너무 느리면 대안으로 사용하는 방법
- 이중 기록을 사용하면 데이터가 변할 때마다 애플리케이션 코드에서 명시적으로 각 시스템에 기록
- 데이터베이스에 기록
- 검색 색인을 갱신
- 캐시 엔트리 무효화
이중 기록의 심각한 문제
- 각 클라이언트가 동시에 아이템 X를 업데이트하려고 할때, 타이밍 문제로 데이터가 맞지 않게 될 수 있다.
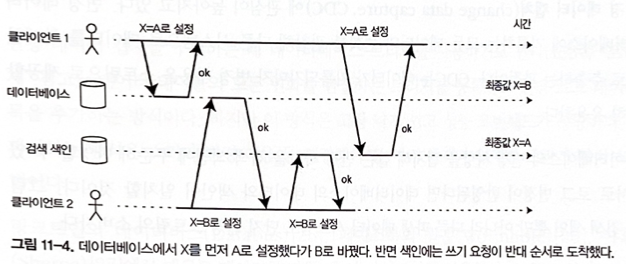
- 동시성 문제
- “동시 쓰기 감지"에서 설명한 버전 벡터와 같은 동시성 감지 매커니즘을 따로 사용하지 않으면 동시에 쓰기 발생해도 알아 차리지 못한다.
- 내결함성 문제
- 한쪽 쓰기가 성공할 때 다른 쪽 쓰기는 실패할 수 있다.
- 두 시스템 간에 불일치가 발생하는 현상이 발생한다.
- 동시성 또는 동시 실패 보장하는 방식은 원자적 커밋 문제다. 이 문제를 해결하는 데는 비용이 많이 든다.
2.2 변경 데이터 캡처
변경 데이터 캡처(change data capture, CDC)
- 데이터베이스에 기록하는 모든 데이터의 변화를 관찰해 다른 시스템으로 데이터를 복제할 수 있다는 추출 과정이다.
- 데이터가 기록되자마자 변경 내용을 스트림으로 제공에 유용
- 데이터베이스의 변경 사항을 캡쳐해 같은 변경 사항을 검색 색인에 꾸준히 반영할 수 있다.
- 같은 순서로 로그 변경이 반영된다면 데이터베이스의 데이터와 색인이 일치할 것이다.

2.2.1 변경 데이터 캡처의 구현
변경 데이터 캡처란?
- 파생 데이터 시스템이 레코드 시스템의 정확한 데이터 복제본을 가지게 하기 위해 레코드 시스템에 발생하는 모든 변경 사항을 파생 데이터 시스템에 반영하는 것을 보장하는 메커니즘
- 본질적으로 변경 사항을 캡처할 데이터베이스 하나를 리더로 하고 나머지를 팔로워로 한다.
- 로그 기반 메시지 브로커는 메세지 순서를 유지하기 때문에 원본 데이터베이스에서 변경 이벤트를 전송하기에 적합하다.
변경 데이터 캡처의 동작
- 비동기 방식으로 동작한다.
- 장점
- 데이터베이스는 변경 사항이 소비자에게 적용될 때가지 기다리지 않고 바로 커밋한다.
- 느린 소비자가 추가되어도 시스템에 미치는 영향이 적다.
- 단점
- 복제 지연의 모든 문제가 발생한다.
2.2.2 로그 컴팩션
로그 컴팩션 동작 원리
- 저장 엔진은 주기적으로 같은 키의 로그 레코드를 찾아 중복 제거한다.
- 각 키에 대한 가장 최근에 갱신된 내용만 유지한다.
- 컴팩션 병합 과정은 백그라운드로 실행한다.
로그 기반 메시지 브로커
- CDC 시스템에서 모든 변경에 기본키가 포함되게 한다.
- 키의 모든 갱신이 해당 키의 이전 값을 교체한다면 특정 키에 대한 최신 쓰기만 유지하면 충분하다.
2.3 이벤트 소싱
이벤트 소싱(event sourcing)
- 도메인 주도 설계(domain-driven design, DDD) 커뮤니티에서 개발한 기법이다.
- 애플리케이션 상태 변화를 모두 변경 이벤트 로그로 저장한다.
이벤트 데이터 캡처와 이벤트 소싱 차이점
- 이벤트 데이터 캡처
- 애플리케이션은 데이터베이스를 변경 가능한 방식으로 사용해 레코드를 자유롭게 갱신하고 삭제한다.
- 추가(O) 갱신(O), 삭제(O)
- 변경 로그는 데이터베이스에서 추출한 쓰기 순서가 실제로 데이터를 기록한 순서와 일치한다.
- 데이터베이스에 기록한 애플리케이션은 CDC가 실행 중인지 알 필요가 없다.
- 애플리케이션은 데이터베이스를 변경 가능한 방식으로 사용해 레코드를 자유롭게 갱신하고 삭제한다.
- 이벤트 소싱
- 애플리케이션 로직은 이벤트 로그에 기록된 불변 이벤트를 기반으로 명시적으로 구축한다.이는 단지 추가만 가능하고 갱신이나 삭제는 권장하지 않거나 금지한다는 것의 의미한다.
- 추가(O) 갱신(X), 삭제(X)
- 이벤트는 저수준에서 상태 변경을 반영하는 것이 아니라 애플리케이션 수준에서 발생한 일을 반영하게끔 설계 됐다.
- 애플리케이션 로직은 이벤트 로그에 기록된 불변 이벤트를 기반으로 명시적으로 구축한다.이는 단지 추가만 가능하고 갱신이나 삭제는 권장하지 않거나 금지한다는 것의 의미한다.
이벤트 소싱의 이점
- 애플리케이션 관점에서 사용자의 행동을 불변 이벤트로 기록하는 방식
- 애플리케이션을 지속해서 개선하기가 매우 유리하다.
- 디버깅에 도움이 되고, 애플리케이션 버그를 방지한다.
- 이벤트 소싱 접근법을 사용하며 새로 발생한 부수 효과를 기존 이벤트에서 쉽게 분리할 수 있다.
2.3.1 이벤트 로그에서 현재 상태 파생하기
- 마지막 상태를 재구축하기 위해서는 이벤트 전체 히스토리가 필요하다.
- 이벤트는 사용자 행동의 결과로 발생한, 상태 메커니즘이 아닌 사용자 행동 의도를 표현하기 때문이다.
- 그러므로 로그 컴팩션 불가능
2.3.2 명령과 이벤트
- 명령(command) : 처음 도착한 사용자의 요청. 명령은 실패할 수 있다(무결성 위반 등)
- 무결성이 검증되고 명령이 승인 되면 지속성 있는 불변 이벤트가 된다.
- 이벤트 : 생성 시점에 사실(fact)가 된다.
- 변경 및 취소가 되었더라도 기존 정보는 여전히 사실로 남아 있으며, 변경 및 취소는 나중에 추가된 독립적인 이벤트가 된다.
- 이벤트 스트림 소비자가 이벤트를 받은 시점에는 이미 불변 로그의 일부이기 때문에 소비자는 이벤트를 거절 못한다.
- 따라서 명령의 유효성은 이벤트가 되기 전에 동식으로 검증해야 한다.
2.4 상태와 스트림 그리고 불변성
2.4.1 불변 이벤트의 장점
- 버그로 인해 잘못된 데이터가 발생했을 때
- 데이터베이스 : 잘못된 데이터를 기록되었다면, 복구가 매우 어렵다.
- 불변 이벤트 로그 : 추가만 하는 로그를 썼다면 문제 상황 진단과 복구가 훨씬 쉽다.
- 불변 이벤트를 통한 유용한 정보
- 사용자의 행동패턴을 파악해 분석할 수 있다.
2.4.2 동시성 제어
- 이벤트 소싱과 변경 데이터 캡처의 가장 큰 단점은 이벤트 로그의 소비가 대개 비동기로 이뤄진다는 점이다.
- 사용자가 로그에 이벤트를 기록하고, 이어서 파생된 뷰를 읽어도 기록한 이벤트가 아직 뷰에 반영되지 않았을 가능성이 있다.
- 해결책으로 하나는 읽기 뷰의 갱신과 로그에 이벤트를 추가하는 작업을 동기식으로 수행하는 방법이다.
- 이 방법을 쓰려면 트랜잭션에서 여러 쓰기를 원자적 단위로 결합해야 하므로 이벤트 로그와 읽기 뷰를 같은 저장 시스템에 담아야 한다.
- 또는 분산 트랜잭션이 필요하다.
- 반면 이벤트 로그를 현재 상태로 만들면 동시성 제어 측면이 단순해진다.
- 다중 객체 트랜잭션은 단일 사용자 동작이 여러 다른 장소의 데이터를 변경해야 할 때 필요하다.
- 그러면 사용자 동작은 한 장소에서 한 번 쓰기만 필요하다. 즉, 이벤트를 로그에 추가만 하면 되며 원자적으로 만들기 쉽다.
3. 스트림 처리
- 스트림을 처리하는 방법
- 이벤트에서 데이터를 꺼내 데이터베이스나 캐시,검색 색인 또는 유사한 저장소 시스템에 기록하고, 다른 클라이언트가 이 시스템에 해당 데이터를 질의한다.
- 이벤트를 사용자에게 직접 보낸다.
- 이메일 경고, 푸시 알림, 실시간 대시보드
- 하나 이상의 입력 스트림을 처리해 하나 이상의 출력 스트림을 생산한다.
- 스트림 처리자가 입력 스트림을 소비해 추가 전용 방식으로 다른 곳에 출력을 쓴다.
3.1 스트림 처리의 사용
3.1.1 모니터링 시스템
- 스트림 처리는 특정 상황이 발생하면 경고를 해주는 모니터링 목적으로 오랜기간 사용돼 왔다.
- 사기 감시 시스템의 신용카드 사용 패턴
- 금융 시장의 가격 변화 감지
- 공장의 기계 상태 모니터링: 오작동 감지
- 군사 첩보 시스템의 잠재적 침략자의 활동 추적
3.1.2 스트림 분석
- 스트림 분석은 대량의 이벤트를 집계하고 통계적 지표를 뽑는다.
- 특정 유형의 이벤트 빈도 측정
- 특정 기간에 걸친 값의 이동 평균(rolling average) 계산
- 이전 시간 간격과 현재 통계값의 비교
- 통계는 고정된 시간 간격 기준으로 계산한다. 집계 시간 간격을 윈도우(window)라 한다.
- 지난 5분간 서비스에 들어온 초당 질의 수의 평균을 구하기
- 같은 기간 동안의 99분위 응답 시간을 구한다.
3.1.3 구체화 뷰 유지하기
- 데이터베이스 변경에 대한 스트림은 파생 데이터 시스템이 원본 데이터베이스의 최신 내용 동기화.
- 파상 데이터 시스템: 캐시, 검색 색인, 데이터 웨어하우스
- 어떤 데이터셋에 대한 또 다른 뷰를 만들어 효율적으로 질의할 수 있게 하고 기반이 되는 데이터가 변경될 때마다 뷰를 갱신한다.
- 이벤트 소싱에서 애플리케이션 상태는 이벤트 로그를 적용함으로써 유지된다.
3.2 시간에 관한 추론
- 분석 목적으로 스트림을 처리하는 경우 시간을 다뤄야 할 때가 있다.
- 지난 5분 동안 평균(윈도우)
- 스트림 처리 프레임워크는 윈도우 시간을 결정할 때 처리하는 장비의 시스템 시계(처리 시간)를 이용한다.
- 간단하다는 장점이 있음
- 이벤트 생성과 처리 사이의 간격이 무시할 정도로 작다면 합리적이나, 눈에 띌 정도로 처리가 지연되면 문제가 생김
728x90
반응형
'스터디 > 데이터 중심 애플리케이션 설계' 카테고리의 다른 글
| [데이터 중심 애플리케이션 설계] 12. 데이터 시스템의 미래 (0) | 2023.02.15 |
|---|---|
| [데이터 중심 애플리케이션 설계] 10. 일괄 처리 (1) | 2023.02.01 |
| [데이터 중심 애플리케이션 설계] 09. 일관성과 합의 (0) | 2023.01.18 |
| [데이터 중심 애플리케이션 설계] 08. 분산 시스템의 골칫거리 (0) | 2023.01.15 |
| [데이터 중심 애플리케이션 설계] 07. 트랜잭션 (1) | 2023.01.02 |




댓글